Act the Part:
Learning Interaction Strategies for Articulated Object Part Discovery
International Conference on Computer Vision (ICCV) 2021
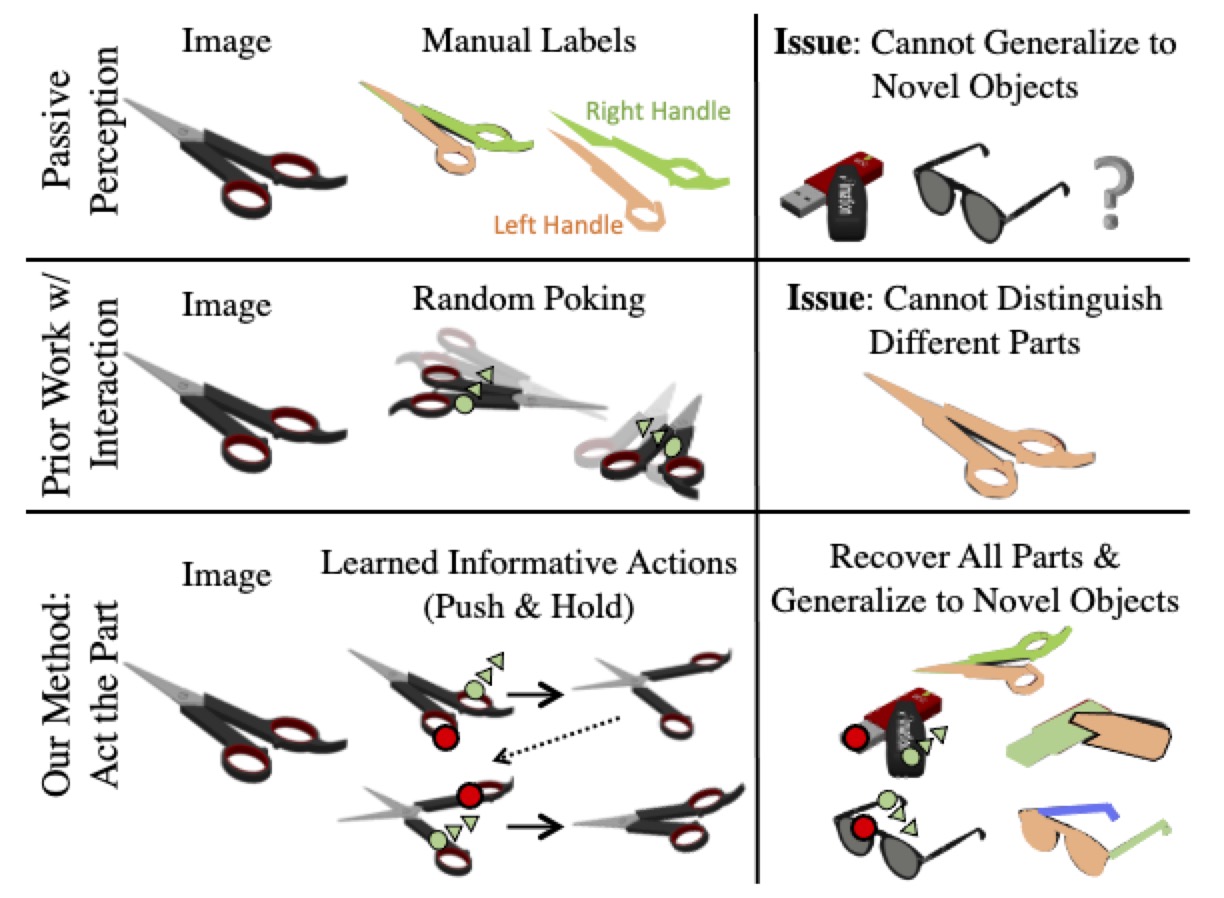
People often use physical intuition when manipulating articulated objects, irrespective of object
semantics.
Motivated by this observation, we identify an important embodied task where an agent must learn to
interact to recover object structures.
To this end, we introduce Act the Part (AtP) to learn how to interact with articulated objects to
discover and segment their parts.
Our key insight is to couple learning interaction and motion prediction, which allows us to isolate
parts and make perceptual part recovery possible without any explicit semantic information.
Our experiments show the AtP model learns efficient strategies for discovering parts, can generalize to
unseen categories, and is capable of conditional reasoning for the task.
Although trained in simulation, we show convincing transfer to real world data with no fine-tuning.
Paper
Latest version: arXiv:2105.01047 [cs.CV] or here

Team



Bibtex
@article{gadre2021act,
title={Act the Part: Learning Interaction Strategies for Articulated Object Part Discovery},
author={Gadre, Samir Yitzhak and Ehsani, Kiana and Song, Shuran},
journal={ICCV},
year={2021} }
Technical Summary Video (with audio)
Conditional Reasoning Demo
Probe the conditional reasoning of our model by (1) selecting an image from a real world unseen category
and (2) selecting a pixel to hold.
The model will output confidence for pushing at a pixel in eight different directions.
Note: the AtP interaction network is running in the browser, so expect ~10s of latency.
(1) Select an image from the following drop down list:
(2) Select a hold pixel by clicking on the image:


Rotations every 45°, so AtP implicitly reasons about pushing in eight directions, while explicitly
reasoning only about pushing right:
Acknowledgements
Thank you Shubham Agrawal, Jessie Chapman, Cheng Chi, the Gadres, Bilkit Githinji, Huy Ha, Kishanee
Haththotuwegama, Gabriel Ilharco Magalhães, Amelia Kuskin, Samuel McKinney, Sarah Pratt, Jackie
Reinhardt, Fiadh Sheeran, Mitchell Wortsman, and Zhenjia Xu for valuable conversations, code, feedback,
and edits. Without you all, this work—and quarantine itself—would not have been possible. Special thanks
to Fiadh Sheeran for the glasses and help filming.
This work was supported in part by the Amazon Research Award and NSF CMMI-2037101.
Contact
If you have any questions, please contact Samir.